一. 前言
目前,市面上流行的redis客户端主要有三个:jedis、Lettuce、Redisson
- Jedis:是Redis 老牌的Java实现客户端,提供了比较全面的Redis命令的支持
Jedis中的方法调用是比较底层的暴露的Redis的API,也即Jedis中的Java方法基本和Redis的API保持着一致,因此其API提供了比较全面的Redis命令的支持
- Redisson:实现了分布式和可扩展的Java数据结构
Redisson中的API进行了比较高的抽象,每个方法调用可能进行了一个或多个Redis方法调用;Redisson实现了分布式和可扩展的Java数据结构。和Jedis相比,功能较为简单,不支持字符串操作,不支持排序、事务、管道、分区等Redis特性。Redisson的宗旨是促进使用者对Redis的关注分离,从而让使用者能够将精力更集中地放在处理业务逻辑上
- Lettuce:高级Redis客户端,用于线程安全同步,异步和响应使用,支持集群,Sentinel,管道和编码器
二. 三大客户端对比
1. 优点
- Jedis:比较全面的提供了Redis的操作特性
- Redisson:促使使用者对Redis的关注分离,提供很多分布式相关操作服务,例如分布式锁,分布式集合,可通过Redis支持延迟队列
- Lettuce:主要在一些分布式缓存框架上使用比较多
2. 伸缩性支持
- Jedis:使用阻塞的I/O,且其方法调用都是同步的,程序流需要等到sockets处理完I/O才能执行,不支持异步。
Jedis客户端实例不是线程安全的,所以需要通过连接池来使用Jedis
- Redisson:基于Netty框架的事件驱动的通信层,其方法调用是异步的。
Redisson的API是线程安全的,所以可以操作单个Redisson连接来完成各种操作
- Lettuce:基于Netty框架的事件驱动的通信层,其方法调用是异步的。
Lettuce的API是线程安全的,所以可以操作单个Lettuce连接来完成各种操作
3. pipeline支持
jedis 通过一定的改造后可以支持pipeline, 具体可以看 Redis 批量操作之pipeline
但是 Lettuce 的pipeline行为很奇怪. 在 Spring RedisTemplate 中的 executePipelined 方法中的情况:
有时完全是一条一条命令地发送
有时全合并几条命令发送
但跟完全 pipeline 的方式不同, 测试多次, 但没发现有一次是完整 pipeline 的
所以如果需要使用pipeline的话, 建议还是使用Jedis
4. 数据结构
- Jedis仅支持基本的数据类型如:String、Hash、List、Set、Sorted Set
- Redisson不仅提供了一系列的分布式Java常用对象,基本可以与Java的基本数据结构通用,还提供了许多分布式服务.
其中包括(BitSet, Set, Multimap, SortedSet, Map, List, Queue, BlockingQueue, Deque, BlockingDeque, Semaphore, Lock, AtomicLong, CountDownLatch, Publish / Subscribe, Bloom filter, Remote service, Spring cache, Executor service, Live Object service, Scheduler service)
5. 关于RedisTemplate的说明
RedisTemplate是SpringDataRedis中对redis API的高度封装
值得关注的是:
springBoot1.×中的默认redis客户端为jedis
springBoot2.×中默认的redis客户端切换为了Lettuce
三. SpringBoot整合实战
下述整合均以SpringBoot2.*为例
1. RedisTemplate + Jedis
2. RedisTemplate + Lettuce
3. Redisson
四. 分布式锁实现
1. 关于分布式锁的简述
锁,是一种多线程下的互斥机制,用来保证并发下的数据安全
1). Java中锁的分类
一般而言,java中的锁分为如下几类:
1. 按”看待线程同步”的角度分
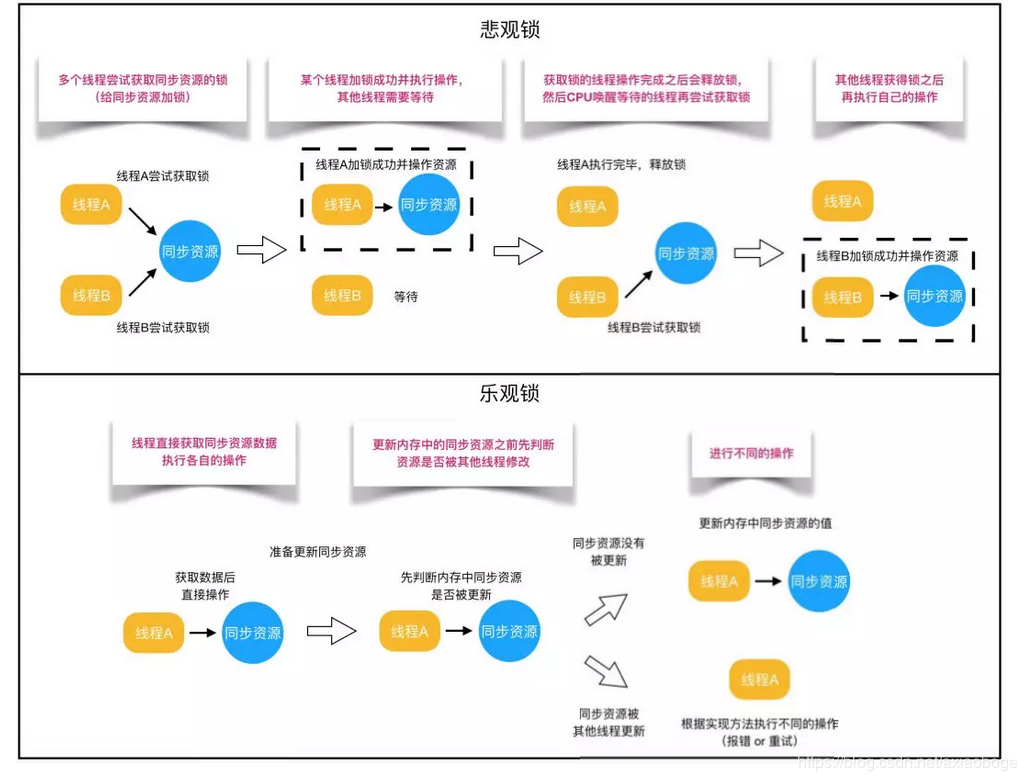
- 悲观锁:同一个数据的并发操作,悲观锁认为自己在使用数据的时候一定有别的线程来修改数据,因此在
获取数据的时候会先加锁,确保数据不会被别的线程修改【诸如java中的:synchronized、Lock】 - 乐观锁:乐观锁认为自己在使用数据时不会有别的线程修改数据,所以不会添加锁,只是在
更新数据的时候去判断之前有没有别的线程更新了这个数据。如果这个数据没有被更新,当前线程将自己修改的数据成功写入。如果数据已经被其他线程更新,则根据不同的实现方式执行不同的操作【Java中通过无锁编程来实现,通常为CAS算法】悲观锁适合写操作多的场景,先加锁可以保证写操作时数据正确乐观锁适合读操作多的场景,不加锁的特点能够使其读操作的性能大幅提升
2. 按”锁的分配优先级”分
- 公平锁:公平锁是指多个线程按照申请锁的顺序来获取锁【Java中的ReentrantLock,根据其构造函数指定该锁是否是公平锁,默认是非公平锁】
- 非公平锁:非公平锁是指多个线程获取锁的顺序并不是按照申请锁的顺序,有可能后申请的线程比先申请的线程优先获取锁。有可能,会造成优先级反转或者饥饿现象【Java中的Synchronized即为非公平锁,其通过AQS实现调度】
非公平锁的优点在于吞吐量比公平锁大
3. 按”是否能被多个线程持有”分
- 独享锁:独享锁是指该锁一次只能被一个线程所持有【Java中的ReentrantLock、Synchronized,即为独享锁】
- 共享锁:共享锁是指该锁可被多个线程所持有【Java中Lock的实现类ReadWriteLock,其读锁是共享锁,其写锁是独享锁】
独享锁与共享锁通过AQS来实现,共享读锁能保证并发读更高效
同时,这部分可以衍生出另外两类锁:互斥锁(ReentrantLock)、读写锁(即ReadWriteLock)
4. 按”锁的状态”分
- 偏向锁:偏向锁是指一段同步代码一直被一个线程所访问,那么该线程会自动获取锁。降低获取锁的代价。
- 轻量级锁:轻量级锁是指当锁是偏向锁的时候,被另一个线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,提高性能
- 重量级锁:重量级锁是指当锁为轻量级锁的时候,另一个线程虽然是自旋,但自旋不会一直持续下去,当自旋一定次数的时候,还没有获取到锁,就会进入阻塞,该锁膨胀为重量级锁。重量级锁会让其他申请的线程进入阻塞,性能降低
关于上文中提及的自旋锁:是指尝试获取锁的线程不会立即阻塞,而是采用循环的方式去尝试获取锁【该方式减少线程上下文切换、但是循环会消耗CPU】
5. 其他锁
- 可重入锁:又名递归锁,是指在同一个线程在外层方法获取锁的时候,在进入内层方法会自动获取锁【Java中的ReentrantLock,及是一个可重入锁;Synchronized也可以通过代码实现可重入】
可重入锁可一定程度避免死锁
1
2
3
4
5
6synchronized void setA() throws Exception{
Thread.sleep(1000); setB();
}
synchronized void setB() throws Exception{
Thread.sleep(1000);
}
2). 分布式锁的定义
分布式锁主要用于解决,分布式系统中对同一数据产生脏读或重复插入问题,一般而言需要满足如下基本要求:
- 互斥性 : 和我们本地锁一样互斥性是最基本,但是分布式锁需要保证在不同节点的不同线程的互斥。
- 可重入性 : 同一个节点上的同一个线程如果获取了锁之后那么也可以再次获取这个锁。锁超时:和本地锁一样支持锁超时,防止死锁。
- 高效,高可用 : 加锁和解锁需要高效,同时也需要保证高可用防止分布式锁失效,可以增加降级。
- 支持阻塞和非阻塞 : 和ReentrantLock一样支持lock和trylock以及tryLock(long timeOut)。
- 支持公平锁和非公平锁(可选) : 公平锁的意思是按照请求加锁的顺序获得锁,非公平锁就相反是无序的。这个一般来说实现的比较少。
2. 分布式锁的常用解决方案
1). 数据库悲观锁
1 | 使用 Select XXXXXXX for update ; 语句 |
注意: 悲观锁的行锁及表锁, 效率低。
使用场景:冲突概率比较高的情况下。
2). 数据库乐观锁
数据库表字段中增加版本号字段,读取数据时将版本号字段一同读出,数据更新时对此版本号进行加1操作。更新过程中会对版本号进行比较,如果一致,没有发生改变,则会成功执行本次操作,如果版本号不一致,则会更新失败。
1 | Select XXX,vesion from some_table where id =XXX |
使用场景:冲突概率比较低的情况。
3). 基于redis的分布式锁
该方案主要是基于Redis的setnx()、expire()来实现分布式锁。
1 | setnx(lockey,1) 如果返回0,则说明占位失败;如果返回1说明站位成功 |
注意:保证Redis的高可用 (Redis 哨兵模式架构,Redis集群模式架构)
使用场景:满足一般的业务需求。
4). 基于Zookeeper的分布式锁(TODO)
主要基于zookeeper 节点名称的唯一性
5). 基于MQ的分阶段提交(TODO)
3. Jedis实现
Jedis的实现,本质上还是基于redis的原生api。主要有如下三大要点:
- set命令要用set key value px milliseconds nx
- value需要具有唯一性
- 释放锁时要验证value值,不能误解锁
1) 基于set key value px milliseconds nx实现
1 | public long transactionLock(final String lockKey, String threadName){ |
2). 基于setNX实现(不建议使用)
setNX易导致死锁
1 | public boolean setNX(final String key, final String value) { |
3). 基于事务实现(不建议使用)
redis集群下不可用
1 | public synchronized long lock(String lockKey, String threadName) { |
4). 基于lua脚本实现
1 | public void scriptUnLock(final String lockKey, final long lockValue, String threadName) { |
4. Redisson实现(*)
上述基于jedis的分布式锁实现中,存在加锁时只作用于单个节点,如果发生节点挂掉(cluster模式),或者主从切换时(sentine模式),会出现锁丢失的请况,为便于理解,举一个例子:
- 在Redis的master节点上拿到了锁;
- 但是这个加锁的key还没有同步到slave节点;
- master故障,发生故障转移,slave节点升级为master节点;
- 导致锁丢失
正因为如此,Redis作者antirez基于分布式环境下提出了一种更高级的分布式锁的实现方式:Redlock
1). Redlock算法
在Redis的分布式环境中,我们假设有N个Redis master。这些节点完全互相独立,不存在主从复制或者其他集群协调机制。我们确保将在N个实例上使用与在Redis单实例下相同方法获取和释放锁。现在我们假设有5个Redis master节点,同时我们需要在5台服务器上面运行这些Redis实例,这样保证他们不会同时都宕掉
为了取到锁,客户端应该执行以下操作:
- 获取当前系统时间,以毫秒为单位。
- 依次尝试从5个实例,使用相同的key和具有唯一性的value(例如UUID)获取锁。
1
当向Redis请求获取锁时,客户端应该设置一个网络连接和响应超时时间,这个超时时间应该小于锁的失效时间。例如你的锁自动失效时间为10秒,则超时时间应该在5-50毫秒之间。这样可以避免服务器端Redis已经挂掉的情况下,客户端还在死死地等待响应结果。如果服务器端没有在规定时间内响应,客户端应该尽快尝试去另外一个Redis实例请求获取锁。
- 客户端使用当前时间减去开始获取锁时间(步骤1记录的时间)就得到获取锁使用的时间。
1
当且仅当从大多数(N/2+1,这里是3个节点)的Redis节点都取到锁,并且使用的时间小于锁失效时间时,锁才算获取成功。
- 如果取到了锁,key的真正有效时间等于有效时间减去获取锁所使用的时间(步骤3计算的结果)。
- 如果因为某些原因,获取锁失败(没有在至少N/2+1个Redis实例取到锁或者取锁时间已经超过了有效时间),客户端应该在所有的Redis实例上进行解锁
1
即便某些Redis实例根本就没有加锁成功,防止某些节点获取到锁但是客户端没有得到响应而导致接下来的一段时间不能被重新获取锁
2). Redlock源码
redisson已经有对redlock算法封装
1. 唯一ID获取
实现分布式锁的一个非常重要的点就是set的value要具有唯一性,redisson的value是怎样保证value的唯一性呢?答案是UUID+threadId。入口在redissonClient.getLock(“REDLOCK_KEY”),
源码在Redisson.java和RedissonLock.java中:
1 | protected final UUID id = UUID.randomUUID(); |
2. 获取锁
获取锁的代码为redLock.tryLock()或者redLock.tryLock(500, 10000, TimeUnit.MILLISECONDS),两者的最终核心源码都是下面这段代码,只不过前者获取锁的默认租约时间(leaseTime)是LOCK_EXPIRATION_INTERVAL_SECONDS,即30s
获取锁的命令中:
KEYS[1]就是Collections.singletonList(getName()),表示分布式锁的key,即REDLOCK_KEY;ARGV[1]就是internalLockLeaseTime,即锁的租约时间,默认30s;ARGV[2]就是getLockName(threadId),是获取锁时set的唯一值,即UUID+threadId:
1 | <T> RFuture<T> tryLockInnerAsync(long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) { |
3. 释放锁
释放锁的代码为redLock.unlock(),核心源码如下
1 | protected RFuture<Boolean> unlockInnerAsync(long threadId) { |
2). Redisson实践
- 引入pom
1 | <dependency> |
配置类
1
2
3
4
5
6
7
8
9
10
11
12
13Config config = new Config();
config.useClusterServers()
.setScanInterval(2000) // cluster state scan interval in milliseconds
.addNodeAddress("redis://127.0.0.1:7000", "redis://127.0.0.1:7001")
.addNodeAddress("redis://127.0.0.1:7002");
RedissonClient redisson = Redisson.create(config);
RLock lock = redisson.getLock("anyLock");
lock.lock();
try {
...
} finally {
lock.unlock();
}加锁
1 | Config config1 = new Config(); |

