一. 前言
目前,绩效考核项目中采集、计算、传播分析功能中均使用到了定时任务,具体而言有如下刚性诉求:
- 支持动态配置
- 支持分布式、集群部署,且满足一致性
- 开源且有完善的文档
- 外部依赖少,便于部署
二. 单机-Java定时任务框架列举
1. Thread
借助线程类Thread,利用循环和sleep方法来实现定时任务效果
1 | public class Job_Schedule_Test1 { |
2. Timer/TimerTask
Timer/TimerTask`:Timer是一个定时器类,通过该类可以为指定的定时任务进行配置.TimerTask类是一个定时任务类,该类实现了Runnable接口
- 当启动和去取消任务时可以控制
- 第一次执行任务时可以指定你想要的delay时间
- 缺点是异常未检查会中止线程
1 | import java.util.Timer; |
3. ScheduledExecutorService
ScheduledExecutorService:源自java.util.concurrent包,做为并发工具类被引进。相对延迟或者周期作为定时任务调度,缺点没有绝对的日期或者时间
- 相比于Timer的单线程,它是通过线程池的方式来执行任务
- 可以很灵活的去设定第一次执行任务delay时间
- 提供了良好的约定,以便设定执行的时间间隔
综合使用ScheduledExecutorService 和 Calendar 可以实现复杂任务调度
1 | import java.util.concurrent.Executors; |
3. Spring Scheduler(*)
Spring Scheduler:配置简单功能较多,如果系统使用单机的话可以优先考虑spring定时器
1 | // 需要在启动类中加入@EnableScheduling注解,启用定时任务的配置 |
4. Quartz
Quartz是Java事实上的定时任务标准。但Quartz关注点在于定时任务而非数据,并无一套根据数据处理而定制化的流程。虽然Quartz可以基于数据库实现作业的高可用,但缺少分布式并行调度的功能
1 | // Quartz任务类 |
三. 分布式-Java定时任务框架列举
1. elastic-job
elastic-job是当当开发的弹性分布式任务调度系统,采用zookeeper实现分布式协调,实现任务高可用以及分片。去中心化的设计,各个作业节点自治,各自触发调度,存在各个作业服务器时间不一致的问题
该项目已经超过两年未进行更新了,不建议使用
1). 概述
elastic-Job是一个分布式调度解决方案,由两个相互独立的子项目Elastic-Job-Lite和Elastic-Job-Cloud组成。
- elastic-Job-Cloud使用Mesos + Docker的解决方案,额外提供资源治理、应用分发以及进程隔离等服务。
- elastic-Job-Lite定位为轻量级无中心化解决方案,使用jar包的形式提供最轻量级的分布式任务的协调服务,外部依赖仅Zookeeper
推荐搭配:Elastic-Job-Lite+Zookeeper在高可用方案的基础上增加了弹性扩容和数据分片
Elastic-Job提供了如下功能模块:
- 分布式调度协调
- 弹性扩容缩容
- 失效转移
- 错过执行作业重触发
- 作业分片一致性,保证同一分片在分布式环境中仅一个执行实例
- 自诊断并修复分布式不稳定造成的问题
- 支持并行调度
- 支持作业生命周期操作
- 丰富的作业类型
- Spring整合以及命名空间提供
- 运维平台
2). 核心概念
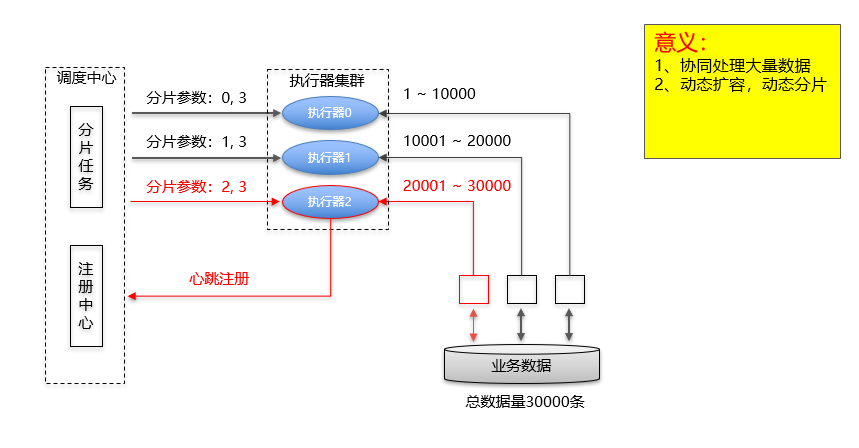
分片概念
任务的分布式执行,需要将一个任务拆分为多个独立的任务项,然后由分布式的服务器分别执行某一个或几个分片项例如:有一个遍历数据库某张表的作业,现有2台服务器。为了快速的执行作业,那么每台服务器应执行作业的50%。
为满足此需求,可将作业分成2片,每台服务器执行1片。作业遍历数据的逻辑应为:服务器A遍历ID以奇数结尾的数据;服务器B遍历ID以偶数结尾的数据。
如果分成10片,则作业遍历数据的逻辑应为:每片分到的分片项应为ID%10,而服务器A被分配到分片项0,1,2,3,4;服务器B被分配到分片项5,6,7,8,9,直接的结果就是服务器A遍历ID以0-4结尾的数据;服务器B遍历ID以5-9结尾的数据分片项与业务处理解耦
Elastic-Job并不直接提供数据处理的功能,框架只会将分片项分配至各个运行中的作业服务器,开发者需要自行处理分片项与真实数据的对应关系分布式调度
Elastic-Job并无作业调度中心节点,而是基于部署作业框架的程序在到达相应时间点时各自触发调度最大限度利用资源
Elastic-Job也提供最灵活的方式,最大限度的提高执行作业的吞吐量。将分片项设置为大于服务器的数量,最好是大于服务器倍数的数量,作业将会合理的利用分布式资源,动态的分配分片项例如:3台服务器,分成10片,则分片项分配结果为服务器A=0,1,2;服务器B=3,4,5;服务器C=6,7,8,9。如果服务器C崩溃,则分片项分配结果为服务器A=0,1,2,3,4;服务器B=5,6,7,8,9。在不丢失分片项的情况下,最大限度的利用现有资源提高吞吐量
2. xxl-job
大众点评员工徐雪里于2015年发布的分布式任务调度平台,是一个轻量级分布式任务调度框架,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。具有如下特点:
- 简单:支持通过Web页面对任务进行CRUD操作,操作简单;
- 动态:支持动态修改任务状态、启动/停止任务,以及终止运行中任务,即时生效;
- 调度中心HA(中心式):调度采用中心式设计,“调度中心”自研调度组件并支持集群部署,可保证调度中心HA;
- 执行器HA(分布式):任务分布式执行,任务”执行器”支持集群部署,可保证任务执行HA;
- 注册中心: 执行器会周期性自动注册任务, 调度中心将会自动发现注册的任务并触发执行。同时,也支持手动录入执行器地址;
- 弹性扩容缩容:一旦有新执行器机器上线或者下线,下次调度时将会重新分配任务;
- 路由策略:执行器集群部署时提供丰富的路由策略,包括:第一个、最后一个、轮询、随机、一致性HASH、最不经常使用、最近最久未使用、故障转移、忙碌转移等;
- 故障转移:任务路由策略选择”故障转移”情况下,如果执行器集群中某一台机器故障,将会自动Failover切换到一台正常的执行器发送调度请求。
- 阻塞处理策略:调度过于密集执行器来不及处理时的处理策略,策略包括:单机串行(默认)、丢弃后续调度、覆盖之前调度;
- 事件触发:除了”Cron方式”和”任务依赖方式”触发任务执行之外,支持基于事件的触发任务方式。调度中心提供触发任务单次执行的API服务,可根据业务事件灵活触发。
- 任务进度监控:支持实时监控任务进度;
- Rolling实时日志:支持在线查看调度结果,并且支持以Rolling方式实时查看执行器输出的完整的执行日志
1). 概述
xxl-job架构图(V2.1.0版本)
.png)
xxl-job分片任务原理图
2). 核心概念
调度数据库
xxl-job的任务调度,基于关系型数据库实现,表结构解析如下:- xxl_job_lock:任务调度锁表;
- xxl_job_group:执行器信息表,维护任务执行器信息;
- xxl_job_info:调度扩展信息表, 用于保存XXL-JOB调度任务的扩展信息,如任务分组、任务名、机器地址、执行器、执行入参和报警邮件等等;
- xxl_job_log:调度日志表, 用于保存XXL-JOB任务调度的历史信息,如调度结果、执行结果、调度入参、调度机器和执行器等等;
- xxl_job_logglue:任务GLUE日志,用于保存GLUE更新历史,用于支持GLUE的版本回溯功能;
- xxl_job_registry:执行器注册表,维护在线的执行器和调度中心机器地址信息;
- xxl_job_user:系统用户表;
调度中心
统一管理任务调度平台上调度任务,负责触发调度执行,并且提供任务管理平台调度中心支持集群部署,但是有如下要求/建议:
- DB配置保持一致
- 登陆账号配置保持一致
- 集群机器时钟保持一致(单机集群忽视)
- 建议:推荐通过nginx为调度中心集群做负载均衡,分配域名。调度中心访问、执行器回调配置、调用API服务等操作均通过该域名进行
执行器
用于任务的绑定,任务触发调度时将会自动发现注册成功的执行器, 实现任务自动发现功能; 另一方面也可以方便的进行任务分组。每个任务必须绑定一个执行器,执行器实际上是一个内嵌的Server,默认端口9999“执行器”接收到“调度中心”的调度请求时,如果任务类型为“Bean模式”,将会匹配Spring容器中的“Bean模式任务”,然后调用其execute方法,执行任务逻辑。如果任务类型为“GLUE模式”,将会加载GLue代码,实例化Java对象,注入依赖的Spring服务(注意:Glue代码中注入的Spring服务,必须存在与该“执行器”项目的Spring容器中),然后调用execute方法,执行任务逻辑。
运行模式
- BEAN模式:任务以JobHandler方式维护在执行器端;需要结合 “JobHandler” 属性匹配执行器中任务
- GLUE模式(Java):任务以源码方式维护在调度中心;该模式的任务实际上是一段继承自IJobHandler的Java类代码并 “groovy” 源码方式维护,它在执行器项目中运行,可使用@Resource/@Autowire注入执行器里中的其他服务
路由策略
当执行器集群部署时,提供丰富的路由策略- FIRST(第一个):固定选择第一个机器;
- LAST(最后一个):固定选择最后一个机器;
- ROUND(轮询):;
- RANDOM(随机):随机选择在线的机器;
- CONSISTENT_HASH(一致性HASH):每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上。
- LEAST_FREQUENTLY_USED(最不经常使用):使用频率最低的机器优先被选举;
- LEAST_RECENTLY_USED(最近最久未使用):最久为使用的机器优先被选举;
- FAILOVER(故障转移):按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度;
- BUSYOVER(忙碌转移):按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度;
- SHARDING_BROADCAST(分片广播):广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务
3) 关于版本
关于xxl的2.*版本,与1.*版本,有一个比较大的区别在于,2.*将调度中心迁移为了springBoot项目,默认推荐的是jar包部署
V2.0.0 Release Notes: [2018-11-9]
- 调度中心迁移到 springboot;
- 底层通讯组件迁移至 xxl-rpc;
- 提供官方docker镜像,并推送至中央仓库(docker pull xuxueli/xxl-job-admin),更进一步实现产品开箱即用;
V2.1.0 Release Notes: [2019-7-6]
- 自研调度组件,移除quartz依赖:一方面是为了精简系统降低冗余依赖,另一方面是为了提供系统的可控度与稳定性
- 底层表结构重构:移除11张quartz相关表,并对现有表结构优化梳理
- 用户管理:支持在线管理系统用户,存在管理员、普通用户两种角色
- 权限管理:执行器维度进行权限控制,管理员拥有全量权限,普通用户需要分配执行器权限后才允许相关操作
四. 项目实战
1. elastic-job篇
1). 引入maven依赖
1 | <!-- elasticjob相关依赖--> |
2). 配置zookeeper注册中心
1 |
|
3). 添加任务节点到zookeeper
1 | public class ElasticJobHandler { |
simpleJobConfigBuilder相关配置项说明:
- failover : 是否开启任务执行失效转移,开启表示如果作业在一次任务执行中途宕机,允许将该次未完成的任务在另一作业节点上补偿执行,默认false
- overwrite:本地配置是否可覆盖注册中心配置,如果可覆盖,每次启动作业都以本地配置为准,默认false
4). 初始化任务
即启动时,将任务注册至zookeeper上
1 | // 建立启动监听 |
5). 实际执行作业
即具体的业务逻辑,可以通过实现SimpleJob接口来完成
1 |
|
6). 分片具体应用
- 调用外部的分页查询接口(HTTP)时,对分页参数取模最大分片数,让每一次请求的分页参数都均匀落在不同的分片项上
- 查询数据库时,可以对字段值按照分片取模
7). elastic-job可视化监控
elastic-job默认未提供可视化监控功能,可以利用第三方的工具实现,步骤如下:- 在https://github.com/miguangying/elastic-job-lite-console下载zip包,解压并执
bin\start.sh[Linux环境],bin\start.bat[windows环境]
- 通过
http://ip:8899/可访问(默认端口号8899,可在start.bat,start.sh中修改) - 初始管理员账号root 密码root (可通过conf\auth.properties修改用户名及密码)
- 在https://github.com/miguangying/elastic-job-lite-console下载zip包,解压并执
登录完展示以下首页:
该工具支持以下功能:
- 查看作业以及服务器状态
- 快捷的修改以及删除作业设置
- 启用和禁用作业
- 跨注册中心查看作业
- 查看作业运行轨迹和运行状态
2. xxl-job篇
1). 搭建调度中心
基于官方提供的xxl-job-admin项目进行改造
i. 初始化数据库
初始化脚本地址:/xxl-job/doc/db/tables_xxl_job.sql
ii. 配置调度中心
即xxl-job-admin项目的application.properties配置文件
1 | ### 调度中心JDBC链接:链接地址请保持和 2.1章节 所创建的调度数据库的地址一致 |
iii. 访问调度中心
调度中心访问地址:http://localhost:8080/xxl-job-admin [admin/123456]
该地址同样作为执行器的回调地址
iv. 调度中心集群
要求:
- DB配置保持一致
- 登陆账号配置保持一致
- 集群机器时钟保持一致(单机集群忽视)
建议:
推荐通过nginx为调度中心集群做负载均衡,分配域名。
调度中心访问、执行器回调配置、调用API服务等操作均通过该域名进行
v. Docker版调度中心
- 下载镜像
1 | // Docker地址:https://hub.docker.com/r/xuxueli/xxl-job-admin/ (建议指定版本号) |
- 创建容器并运行
1
2
3
4
5
6docker run -p 8080:8080 -v /tmp:/data/applogs --name xxl-job-admin -d xuxueli/xxl-job-admin
/**
* 如需自定义 mysql 等配置,可通过 "PARAMS" 指定,参数格式 RAMS="--key=value --key2=value2" ;
* 配置项参考文件:/xxl-job/xxl-job-admin/src/main/resources/application.properties
*/
docker run -e PARAMS="--spring.datasource.url=jdbc:mysql://127.0.0.1:3306/xxl_job?Unicode=true&characterEncoding=UTF-8" -p 8080:8080 -v /tmp:/data/applogs --name xxl-job-admin -d xuxueli/xxl-job-admin
2). 搭建执行器
i. 引入pom依赖
1 | <!-- xxl-job相关依赖 --> |
ii. 新增执行器组件配置
1 |
|
3). 编写Bean模式任务
i. 简单任务
集成IJobHandler抽象类,重写ReturnT()、init()、destroy()方法
1 | (value="demoJobHandler") |
2. 分片任务
1 | (value="shardingJobHandler") |
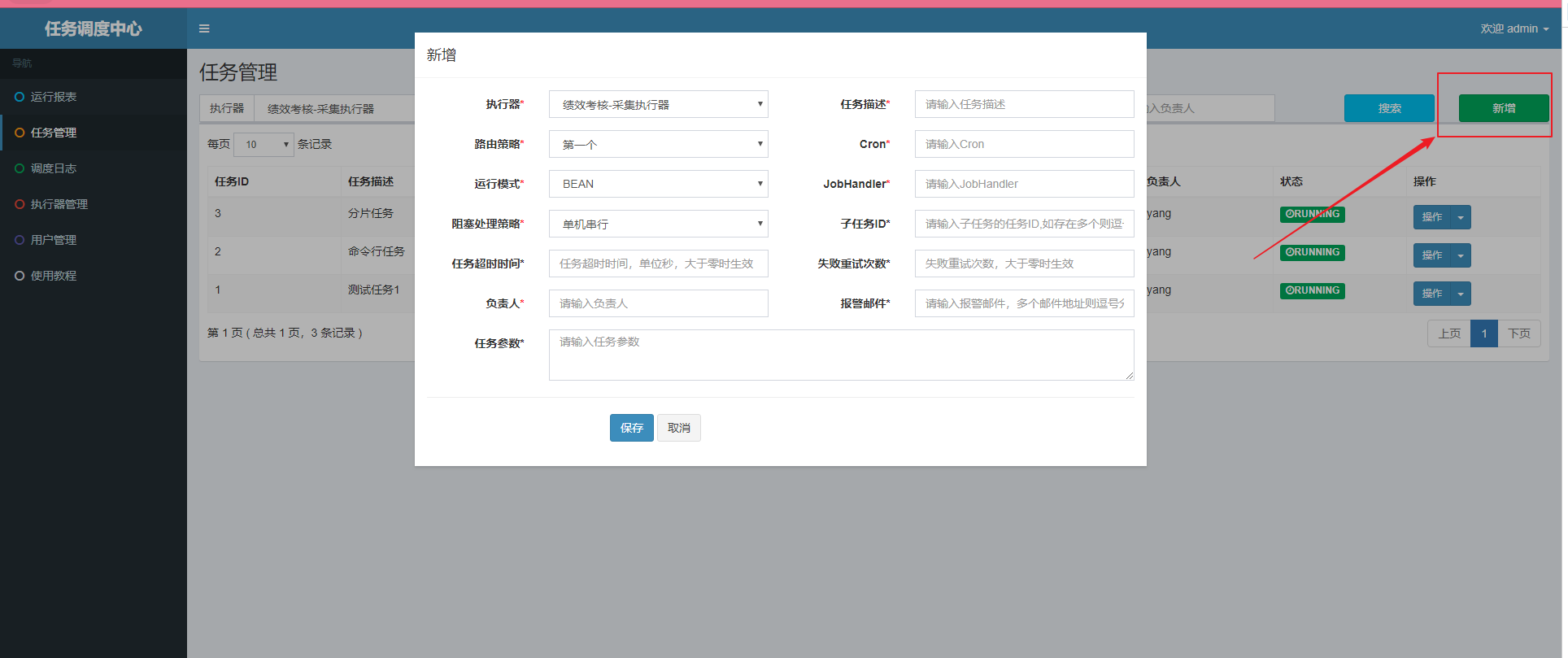
4). 注册任务
最简单的方式,可以通过在xxl-job-admin的管理页面进行新增